
Eventual Consistency Explained With Pizza, Traffic Jams, and One Very Confused Postman
The 5-Second Rule of Distributed Systems (No, Not the Food One) - You built the system. You tested the system. The system works. So why is it lying to you in production?


You order a pizza online. The app says “Order Confirmed!”
You get a push notification: “Your pizza is being prepared!” Then another: “Your driver is on the way!” Then your doorbell rings — and it’s your neighbor returning a drill you lent him three weeks ago.
Two minutes later, the pizza arrives. Moments after that, your phone buzzes one more time: “Your driver has picked up your order.”
Wait… What?
Welcome to distributed systems. The pizza arrived before the notification that it was coming. The events were real. The sequence was a lie. And somehow, everything worked out fine.
This is called eventual consistency — one of the most elegant ideas in computer science. It’s also one of the most reliable sources of 2 am production incidents.
The Mindset Shift That Changes Everything
Most of us learned to program in a world where things happen in order:
Line 1 runs.
Then line 2.
You call a function, it returns a value, you use the value.
Cause precedes effect. Time is a straight line. Distributed systems require you to throw that model in the bin.
In a distributed system, everything is a message, and messages arrive when they feel like it. Your job is not to force order onto a chaotic world — it’s to design a system that handles chaos gracefully. The mindset shift is this: stop thinking about when things happen and start thinking about whether your system can survive any ordering of events.
Think of it like being a post office sorting center. You don’t control when letters arrive. You don’t know if the letter saying “I’m getting married” will arrive before or after the letter saying “come to my wedding.”
Your job is to process each letter correctly regardless of arrival order, and never take an action you can’t undo if a contradicting letter shows up later.
Why This Keeps Happening (The Reasons Are Everywhere)
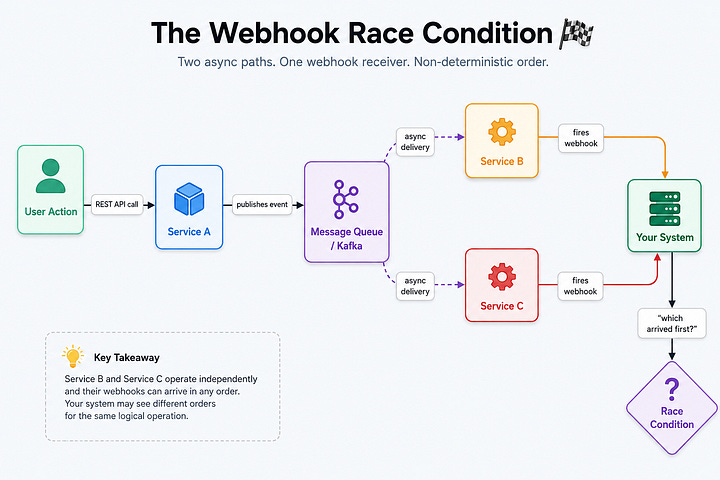
Scenario 1: The Kafka Chain
You place an e-commerce order:
The order service publishes to Kafka.
The inventory service consumes it and reserves stock.
The notification service consumes it and sends you an email.
The analytics service consumes it and updates dashboards.
All three consumers read the same event — but in their own time. The email might arrive before your dashboard updates. The inventory reservation might briefly show the item as available to another customer. Nothing is wrong. Everything is eventual.
Scenario 2: The Microservice Telephone Game
Service A calls Service B, which calls Service C, which sends a webhook back to Service A.
By the time the webhook arrives, Service A has already moved on. Maybe it retried and processed the request a second time. Now it gets a success notification for work it already redid.
If Service A isn’t idempotent — if it doesn’t check “have I already handled this?” — it will act twice. Your user gets charged twice. Your database has a duplicate row. Your on-call engineer has a very bad night.
Scenario 3: The Failover Ghost
A primary database node fails. The system fails over to the replica. Inflight requests hit the new primary.
But some events — queued, in-flight, already serialized — are still addressed to the old node’s state. They arrive late, after the failover, carrying stale assumptions. Your system has to recognize them, handle them gracefully, and not corrupt the new state.
Scenario 4: The Mobile App Problem
A user books a flight on their phone.
The app confirms the booking optimistically (before the server responds) to feel fast.
The server rejects it — seat taken.
The app’s notification arrives: “Booking confirmed!”
Three seconds later: “Booking failed.”
The user is confused. The events were truthful individually. The sequence was chaos.
The Three Laws of Living With Eventual Consistency
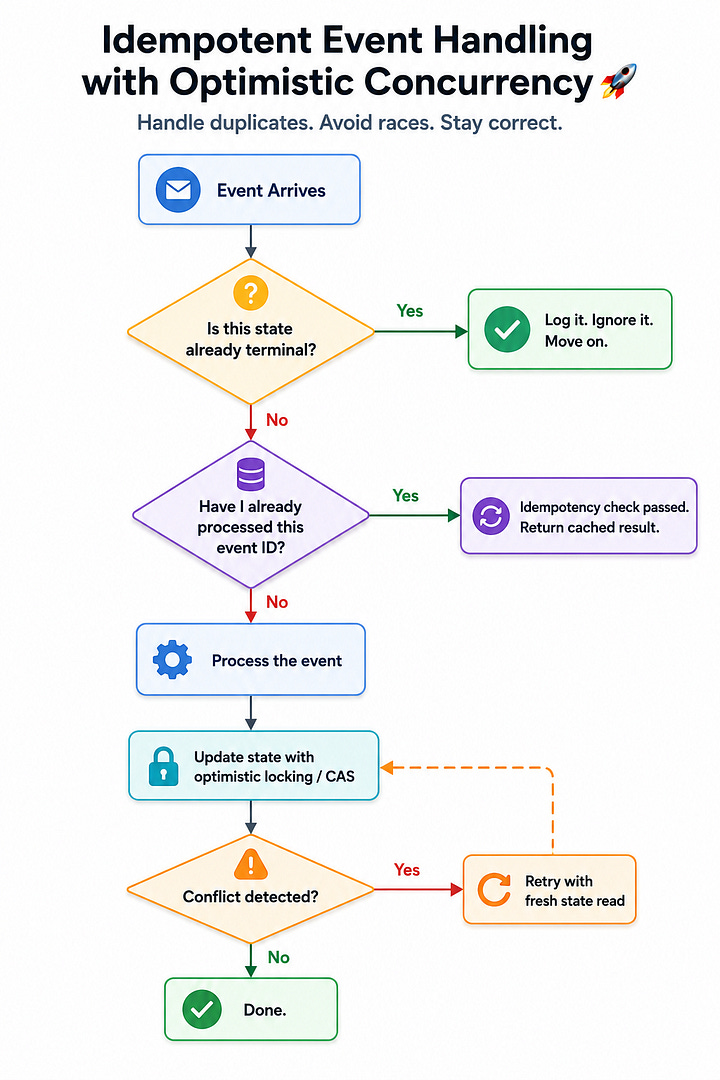
Law 1: Every state transition must be a one-way door — or a revolving one.
When something reaches a terminal state (order cancelled, transaction reversed, account suspended), draw a hard line.
Late-arriving events — “the payment succeeded!” — should bounce off that line, not penetrate it. Log them. Ignore them. Never let a stale event undo a deliberate terminal decision.
Law 2: Idempotency is not optional, it’s oxygen.
Every event handler, every API endpoint, every background job should ask: “What happens if I receive this exact input twice?” If the answer is “bad things,” you have work to do:
Use event IDs.
Use database upserts.
Use CAS (Compare-And-Swap) locks.
Design your system so that replaying an event produces the same outcome as processing it once.
