
The 4 Async Python Traps That Will Wreck Your Production Service (And How to Escape Each One)
Retry logic, connection pools, and silent crashes: The async Python survival guide


It’s 2am. Your on-call phone buzzes. Users are reporting that your checkout service is hanging — not erroring, not returning, just hanging. You check the logs. Nothing. No error, no trace, no stack. The service is alive according to Kubernetes.
It’s just silently doing nothing, like a contractor who took your deposit and stopped answering calls.
You add more logging. You restart pods. An hour later, you find it: a retry loop with no total deadline. Three retries, each waiting up to 7 minutes for a timeout. Your service had been politely waiting 21 minutes before giving up on a single failed request.
Welcome to async Python in production. It’s powerful. It’s elegant. And it will absolutely humble you if you don’t know where the traps are.
The Mindset: Async Is Optimistic by Default
Synchronous code fails loudly. Async code fails quietly.
A hung coroutine doesn’t crash your process — it just sits there, holding resources, blocking progress, looking fine from the outside.
The mindset shift you need:
Assume things will hang, not just fail. Design every async boundary with a timeout, a deadline, and an escape hatch.
Trap 1: The Retry Loop With No Total Deadline
Retry logic is table stakes for resilient services. But most implementations look like this:
Looks reasonable. Three attempts, exponential backoff.
Except: 3 attempts × 420 second timeout = 21 minutes before your caller gets an error. During that time the calling request is frozen. The connection pool slot is occupied. Downstream queues back up.
The fix is a total deadline wrapping the entire retry loop — not just each individual attempt.
async with anyio.fail_after(60): # hard ceiling: 60s total, no matter what
await call_with_retries()Think of it like a contractor job: each individual task can have its own time estimate, but the whole project needs a completion date. Without it, “almost done” becomes infinite.

Trap 2: asyncio.TaskGroup Swallows Your Errors Silently
Python 3.11 introduced asyncio.TaskGroup — a clean way to run concurrent tasks. It’s great. It also has a sharp edge almost nobody knows about.
When a task inside a TaskGroup raises an exception, Python wraps it in an ExceptionGroup. If your web framework (Starlette, FastAPI, Django ASGI) receives an ExceptionGroup it wasn’t designed to handle, it doesn’t log it, doesn’t return a 500 — it just crashes the handler silently. No metrics. No trace. No alert.
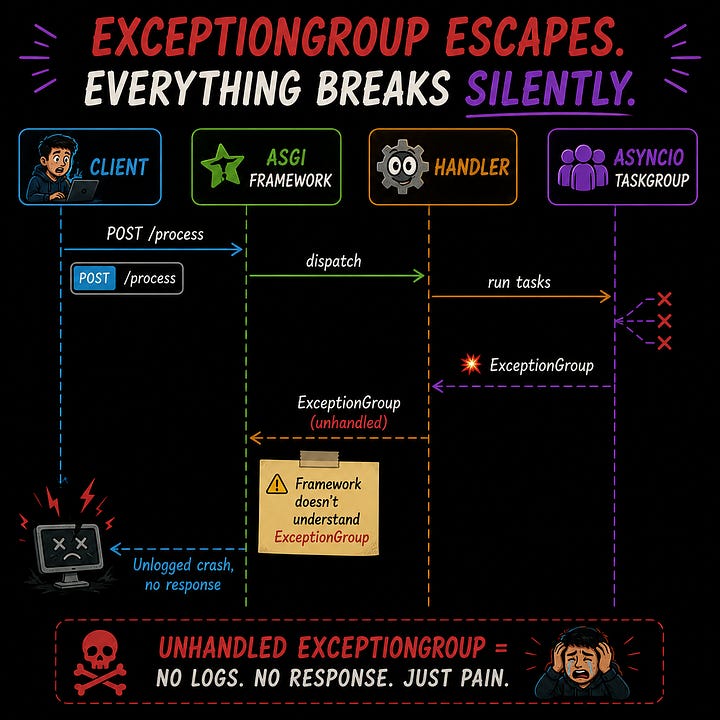
The fix is Python 3.11’s except* syntax — designed specifically for this:
try:
async with asyncio.TaskGroup() as tg:
tg.create_task(do_work())
tg.create_task(handle_request())
except* Exception as eg:
logger.error(”tasks failed”, errors=[str(e) for e in eg.exceptions])
return PlainTextResponse(”Internal Server Error”, status_code=500)
except* is to except what a net is to a tightrope - it catches the whole group, not just one exception at a time.