
The Kubernetes Mortality Rate: Everything That Can Kill Your Pod (And Probably Will)
The fix isn't "prevent the pod from crashing." The fix is: assume the pod will crash, and make your system handle it.
It’s Saturday. Your phone is buzzing. The on-call alert says the service is down.
You SSH in, run kubectl get pods, and see it staring back at you like a crime scene photo: CrashLoopBackOff. Again.
You added more retries last week. You increased the memory limits. You lit a candle in front of your laptop. Nothing works. The pod dies. Comes back. Dies again. At some point you start to feel personally victimized by a container runtime.
Here’s the thing nobody tells you when you graduate from “I deploy to a VPS” to “I’m cloud-native now”:
Kubernetes is not a more reliable version of your old server. It’s a fundamentally different relationship with reliability. And if you approach it the same way, your pods will keep dying and you’ll keep losing sleep.
Let’s talk about it.
Cloud-Native Is a Different Game
Traditional deployment philosophy: your server should never go down. You babysit it. You patch it in place. You add a cron job that restarts the process if it crashes. You name the server “prod-1” and feel a quiet attachment to it.
Kubernetes philosophy: everything dies eventually, and that’s fine, actually.
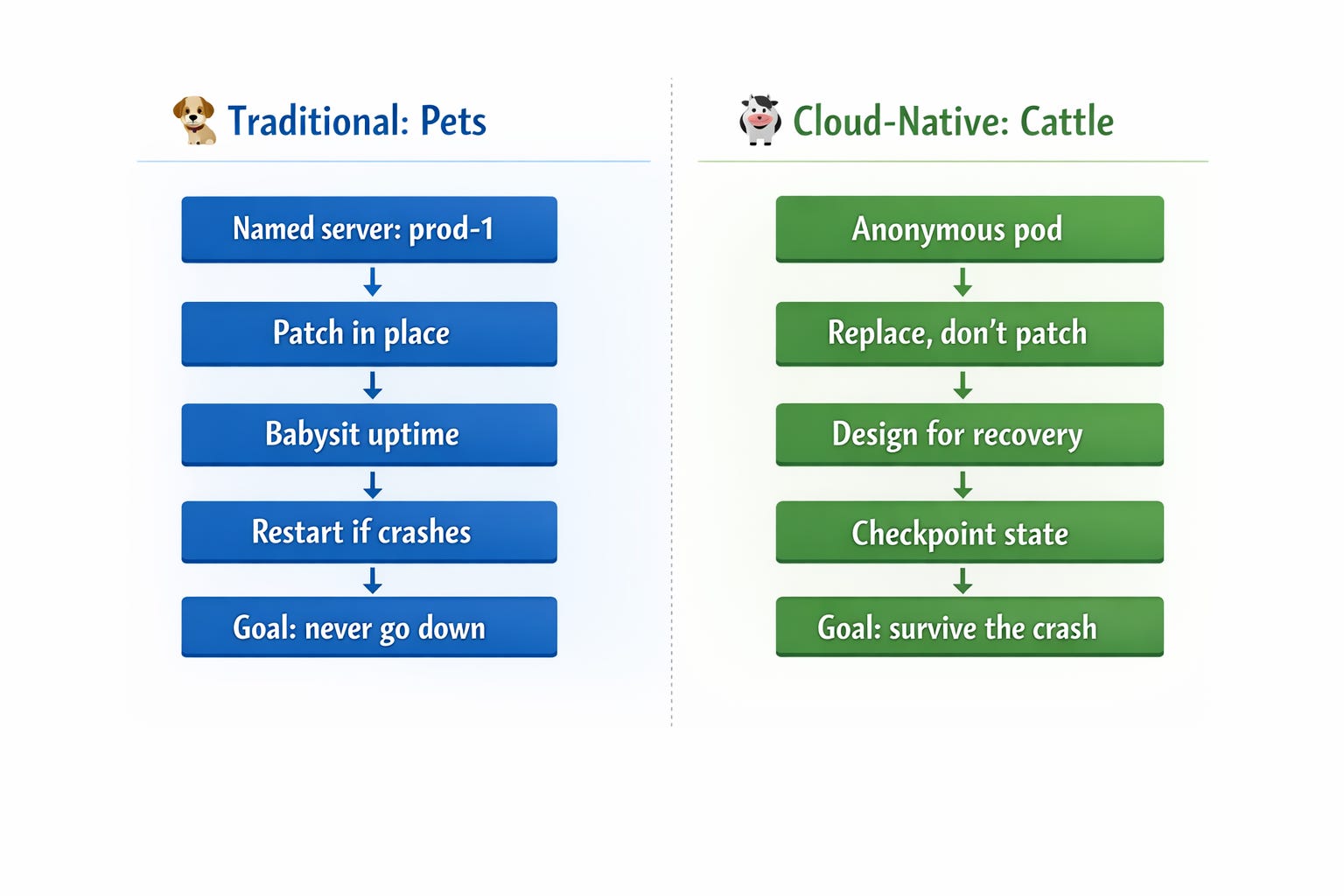
In a cloud-native world, pods are cattle, not pets. They’re expected to be ephemeral. The system is designed around the assumption that individual instances will fail, and resilience comes from the cluster recovering — not from any single pod living forever.
The mental model shift is huge: you’re no longer trying to prevent failure, you’re designing for recovery.
This means your application code has to be written differently:
Startup must be fast.
Shutdown must be graceful.
State can’t live in memory.
And if your process takes 90 seconds to start or 60 seconds to cleanly shut down, you’re going to have a bad time.
“But I’m Not Using Spot Nodes!”
The most common excuse: “I don’t use spot instances or preemptible nodes, so my pods shouldn’t be dying.”
Oh, sweet summer child.
Spot nodes are just one of about a dozen ways Kubernetes will happily terminate your pod. Here’s the uncomfortable list:

